Kafka provides developers an ecosystem in where millions of messages can be processed in a distributed fashion - allowing teams to build massive data ingestion platforms. One of the key aspects, not only to Kafka, but to any distributed messaging platform - is message delivery semantics. Defining these semantics is important, because it requires the developer to think about what happens to a message under failure - which happens all the time.
Kafka provides three delivery semantics out of the box, which can be configured directly onto the producer’s configuration - all three with different use cases. They are
-
at most once semantics: offers the highest throughput of sent messages - but the least durability of written messages.
-
at least once semantics: offers strong durability of written messages - messages are always written. However under failures messages could be duplicated.
-
exactly once semantics: offers the strongest durability of written messages - messages are written exactly once - even under failure.
at most once and at least once semantics are the easiest to configure - both just require fine tuning various settings on the Kafka producer/consumer. However - for exactly once semantics - it requires fine tuning settings on both the kafka producer and consumer, as well as writing application side code for transactions that enable exactly once processing and delivery of messages.
side note - these semantics apply to both the delivery of a message by a producer - and the receipt/processing of a message from the consumer. These semantics can be mixed and matched with each other if different guarantees are needed for the flow of delivery ⟹ processing work cycle. exactly once semantics is able to offer the strongest guarantees on both the producer and consumer.
At Most Once Semantics and At Least Once Semantics
Before getting to exactly once semantics - we’ll go over the two basic settings on both the producer and consumer side.
-
at most once semantics:
- Delivery: Messages are delivered to the topic at most once. Configuring at most once means that when a producer sends a message - it will only send the message at most one time. This means that the producer doesn’t have to wait for an acknowledgement from the leader - and can process/send messages asynchronously without handling any retries or acknowledgements - providing the fastest throughput and latency of all the semantics. However in cases of a failure - messages can be lost.
- to configure at most once semantics
- set
retries=0 - set
acks=0, since you’re not waiting for any acknowledgement from the leader. - set
enable.idempotence=false- as setting it to true will conflict with the other settings. (Kafka will automatically set this for you)
- set
- In short - this can be seen as fire and forget
- to configure at most once semantics
- Processing: Messages are read by the topic at most once. After the consumer has polled the messages the consumed offset (place in the partition) is committed. Message processing can happen before or after the commit, depending on application logic. In event of failure, it’s not guaranteed that each message will be processed. For example, if the consumer crashes after committing it’s offset - but before processing the messages - the consumer that takes over will continue where the other consumer left off - skipping the message.
- to configure at most once semantics - you usually want to commit offsets after/before processing messages - and that can be done within the application code.
- set
enable.auto.commit=false, and commit right after you poll/batch the messages.
- set
- it’s best to let the consumer handle the auto commit - unless you need exact at most once semantics.
- set
enable.auto.commit=true- however this could process messages multiple times (at least once). This could happen when the consumer has consumed a message - but processed them before committing. Therefore when a consumer dies while processing the messages - but before committing them - the consumer that takes over will reprocess those messages.
- set
- to configure at most once semantics - you usually want to commit offsets after/before processing messages - and that can be done within the application code.
- Delivery: Messages are delivered to the topic at most once. Configuring at most once means that when a producer sends a message - it will only send the message at most one time. This means that the producer doesn’t have to wait for an acknowledgement from the leader - and can process/send messages asynchronously without handling any retries or acknowledgements - providing the fastest throughput and latency of all the semantics. However in cases of a failure - messages can be lost.
-
at least once semantics:
- Delivery: Messages are delivered to the broker at least once. With at least once once delivery, when a producer waits for the broker to acknowledge that message. Once the broker acknowledges that message - it means that the message has been written to that broker (topic) - and depending on the
acksetting, been persisted to that topic. If the acknowledgement fails the producer is free to retry sending the message.- to configure at least once semantics
- set
retriesto the default settings (which is essentially unlimited retries) - set
delivery.timeout.msto an upper bound inmsthat directly correlates toretries - most importantly set
acks=all. Ifacks=0- messages could be lost because the producer can send a message to the broker, but if the message fails to be delivered - or the broker failed, the producer will not wait for any acknowledgement - and theretriessetting will not be invoked. Additionally - ifacks=1, then the leader will acknowledge that the message has been written without replicating it to the followers. Therefore a message could be lost if the leader acknowledges the message - but fails to replicate it to the followers then dies. Whenacks=all- in times of system failure - we know that a message has been successfully written/replicated to a topic because the leader will only acknowledge a successful message IF all in-sync replicas have acknowledged it.
- set
Optionally set
enable.idempotence=true. This setting is generally already set to true - and enables that the producer will have only one copy the message written to the broker. This also effectively sets the delivery semantics to exactly once on the producer’s side. We will go over this more in the exactly once section.- messages are delivered one or more times. In the chance of a system failure - messages are never lost - but may be delivered more than once. With idempotence enabled - you’ve also configured exactly once on the producer side.
also in practice you set
retriesto a high number (the default value), and setrequest.delivery.timeoutto set the duration a producer will retry a message. - to configure at least once semantics
- Processing: Messages are processed by the consumer at least once. In order to configure at least once for the consumer you’ll have to be stricter on how you process messages from the topic-partition and how you commit offsets. To achieve this semantic, the consumer reads a set of messages, processes them, then commits the offsets.
- to configure at least once semantics - you usually want to commit offsets after processing messages. Therefore in the case of failing a batch - messages can be re-consumed at the same offset - or if the consumer fails before committing - it can start again at the same place. This means that messages will be processed at least once.
- set
enable.auto.commit=false, and commit offsets after you process the messages.
- set
- to configure at least once semantics - you usually want to commit offsets after processing messages. Therefore in the case of failing a batch - messages can be re-consumed at the same offset - or if the consumer fails before committing - it can start again at the same place. This means that messages will be processed at least once.
- Delivery: Messages are delivered to the broker at least once. With at least once once delivery, when a producer waits for the broker to acknowledge that message. Once the broker acknowledges that message - it means that the message has been written to that broker (topic) - and depending on the
Failure Scenarios
Let’s go over some common failure scenarios that can occur during message delivery to a topic.
A) Message Ack Fails, But Is Written to the Log
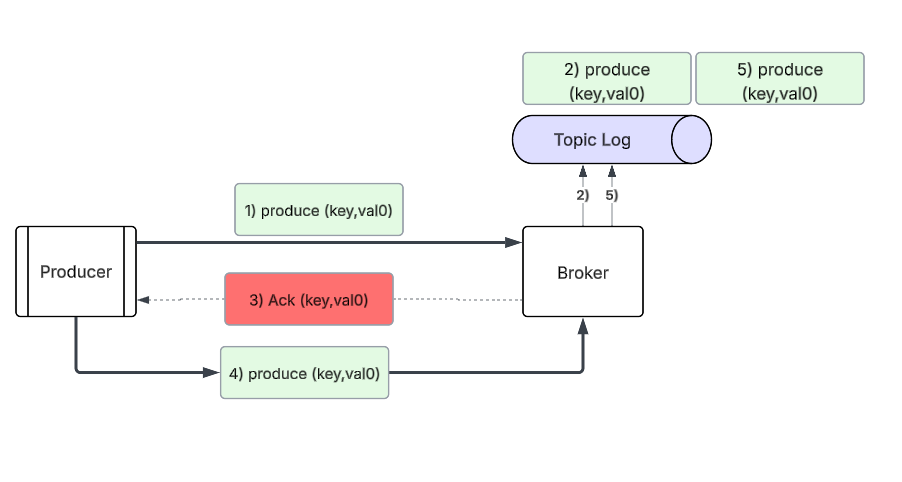
A producer could send over a message to the leader of the topic partition, and the leader is able to successfully write and replicate that record to the topic log. The leader then sends an acknowledgement back to the producer, but that acknowledgement is lost for what ever reason. If your producer is configured with retries then the producer will retry the produce message, and the message will be written twice into the topic partition.
B) Producer Crashes While Processing Messages
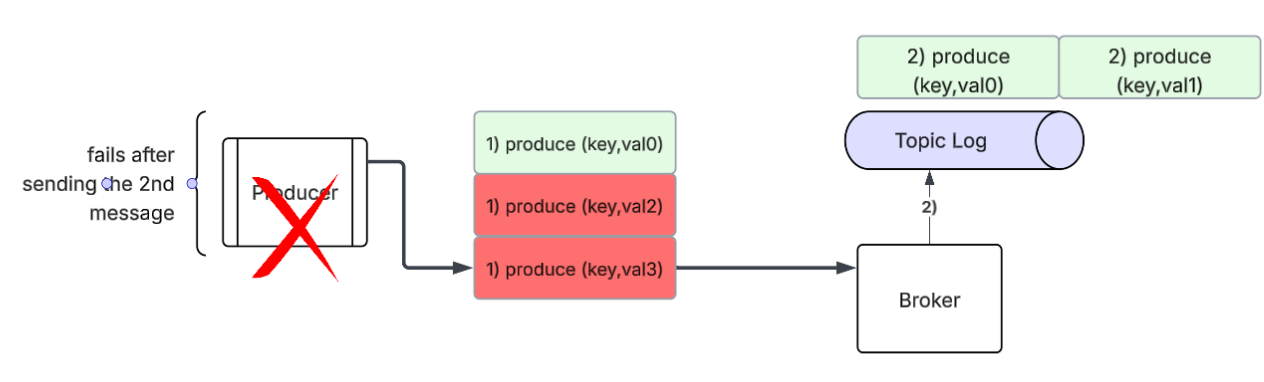
A producer could be in the process of producing many messages to the topic partition, however it crashes half way through. However based on the producer’s application code what should it do? Should it restart from where it left off - which could reintroduce duplicates? If you’re going for at least once delivery semantics, that would be the way to go, or if you’re going for at most once delivery semantics - you would pick up from where it crashes.
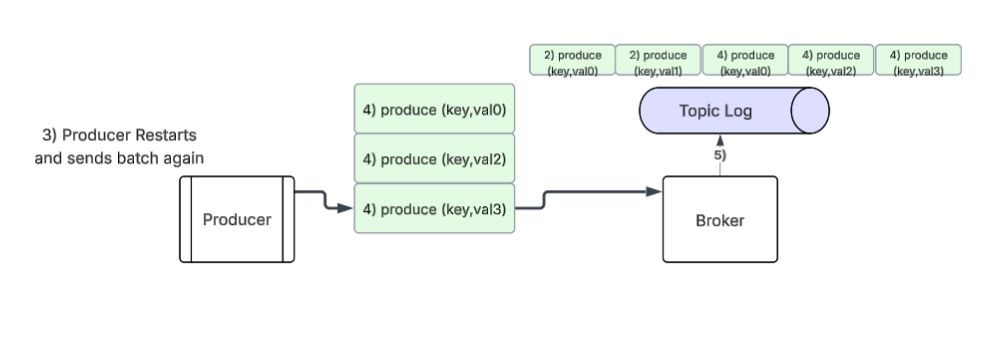
Restarting the producer instance caused the duplicate batch to send again.
C) Consumer Crashes While Processing Messages
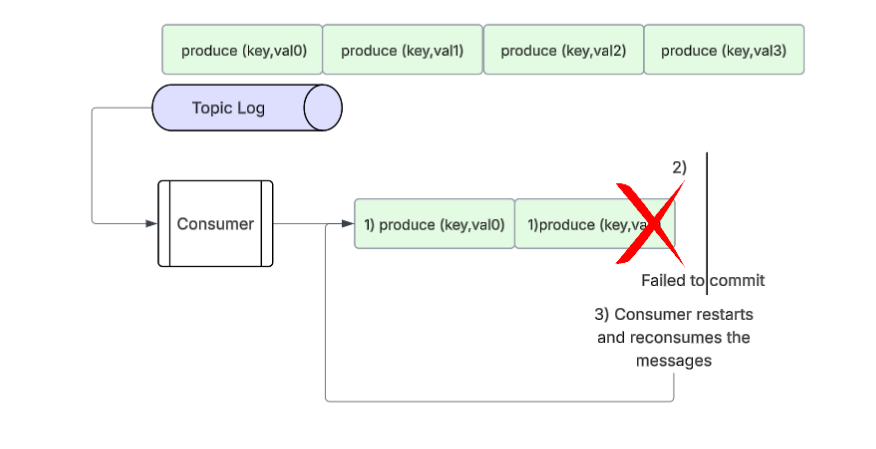
A consumer could fail while in the process of consuming messages from a topic partition. In the event that the consumer crashes before committing their offset - when the consumer is started up again then it will consume the same records again - which introduces duplicates on the consumer side.
As you can see, failures can happen during the producer, broker, and consumer workflow. Depending on how you’ve coded and configured the producer and consumer, you’ll get different delivery and processing semantics on both ends. Depending on the requirements of your architecture - you may be satisfied to leave it off on at least/most once semantics - however some systems require stronger delivery semantics - such as exactly once in both it’s delivery and processing guarantees in face of failures.
Exactly Once Semantics (EOS)
Simply put, in Kafka exactly once means that a message is delivered exactly once to the broker - and processed exactly once by the consumer - even in the event of failure. This not only requires the correct Kafka configuration on the producer/consumer side, but also application logic implementing the transactional API.
We mentioned earlier that the producer can actually implement exactly once delivery by setting acks=all, retries to default, and enable.idempotence=true. This ensures that a message has been delivered to a topic partition exactly one time. This helps solve scenario A) and broker failures. However this doesn’t solve issues B) - as the Kafka producer API does not know the inner workings of your code - and doesn’t solve issue C) since the consumer could fail and reprocess the messages again.
This is where Kafka transactions steps in.
Kafka Transactions
Transactions in Kafka allow atomic multi-partition writes. What this means is that a producer can create atomically write to many topics, and then commit or abort that transaction. If the producer committed that transaction - then the consumers reading from those topics will be able to read those messages. If the producer aborted that transaction - then the consumers reading from those topics will not read those messages.
Ok, so a producer can now perform atomic writes (either all messages are readable or none are). So how exactly does that help for exactly once semantics?
In many Kafka workflows, you’ll have a process consuming messages from a kafka topic, performing some operation on them - and then producing output messages back into another kafka topic. This is called a read - process - write pattern. Processes that employ this pattern can send their consumed offsets back to the __consumed_offsets topic as part of the transaction process - which durably writes their position if the transaction is committed. This is the piece of the puzzle that enables EOS.
If - for some reason - that a process crashes before sending their consumed offsets to the transaction manager and committing, then the downstream consumers won’t be able to see that process’s produces (from a failed transaction) - which is what EOS provides to the consumed and produced messages. The process is now able to retry the transaction with the guarantee that downstream consumers will only see messages once if it succeeds.
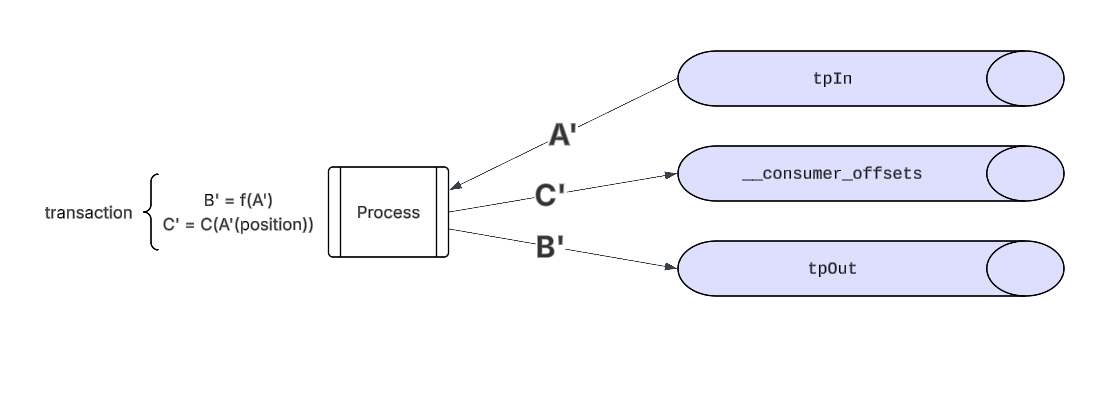
Let’s run over an example: let’s say there’s an input topic tpIn and an output topic tpOut. We have a process that reads in messages from tpIn, performs some function on that message, and produces out to tpOut. The process will then send it’s consumed offsets, C(A’(position)), to __consumer_offsets. Message C’ and B’ are mapped to the transaction - and have become atomic.
Upon a successful commit - downstream consumers will be able to see message B’ - and the process’s position will be durable saved. If there was any failure that occurred during the transaction process - then no messages will be sent out and the process is able to restart from it’s previous offset.
Downstream consumers will only read committed if
isolation.level=read_committedis set. If it’s set toread_uncommittedconsumers will see aborted messages and ongoing transactional messages.
It is important to note that this read - process -write pattern only applies to within the Kafka Ecosystem - meaning the write portion of the pattern only applies to Kafka produces and doesn’t apply to external systems processing.
Transactional.id
Kafka introduces a transactional.id to help combat a zombie. Let’s say that a consumer is lagging behind or we think that it has failed, and we bring up another consumer to perform the task. However, now we have two processes that could be potentially producing multiple duplicate messages. Transactional id’s help prevent this because the producer will have to register it’s ID to a transactional coordinator on startup. When the same transactional.id is seen again, the coordinator will increase it’s epoch - which the coordinator uses to mark which is the most recent producer. Any transaction operation with an older epoch is fenced and the application code could die gracefully.
Transactions Workflow
To help facilitate transactions, Kafka introduces a Transaction Coordinator (TXN Coordinator), a broker chosen to help facilitate requests from the Producers and other brokers.
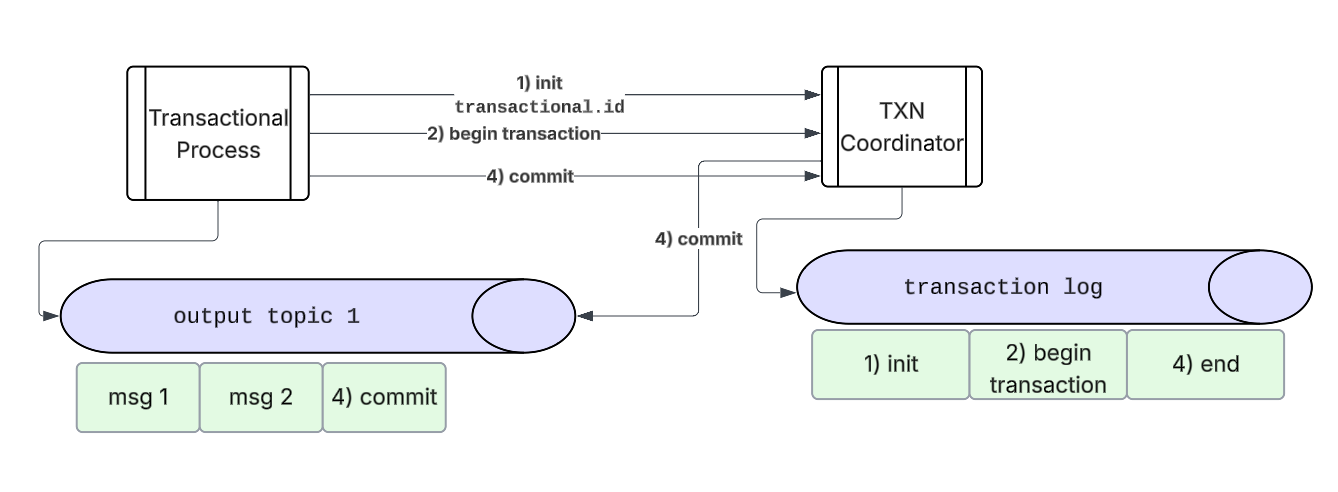
-
Producer & Transaction Coordinator Interaction
- upon startup the producer chooses a
transactional.idand initiates a transaction with the TXN Coordinator.
- upon startup the producer chooses a
-
Txn Coordinator
- The TXN Coordinator keeps track of a transaction log - a durable kafka topic that keeps track of transaction state amongst many different transactions. The producer will send updates to the coordinator to write to this log.
-
Producer
- Producer begins the transaction, which will send a request to the TXN Coordinator to start a transaction.
- Producer can send many different messages to the output topic-partitions
- After the producer processes the messages and wants to commit, the producer will send it’s
consumed_offsetsas part of the transaction to the transaction coordinator. - If all steps were successful - the Producer can commit - marking the transaction as complete - or abort in case of an error.
-
Txn Coordinator to Topic/Partition Interaction
- When the producer commits/aborts - the coordinator starts a two phase commit process.
- 1st phase: The coordinator will update the transaction log to (prepare commit/abort) which will execute no matter what. This will durably mark that a transaction needs to bet committed or aborted. Therefore if the coordinator fails - another one will be able to take it’s place.
- 2nd phase: The coordinator writes commit markers to topic/partitions that are apart of the transactions.
- These commit markers are then used by consumers in
read_committedmode to either use or filter out aborted messages. Once these markers have finished - the coordinator marks the transaction as done.
- When the producer commits/aborts - the coordinator starts a two phase commit process.
Implement EOS Semantics using Kafka Transactions with Rust
Now that we have a basic understanding about Kafka EOS - I’ll show you how to use them using Rust as an example. Hopefully this will better help you understand what’s going during the read-process-write interactions within transactions.
Configuration
To configure a transactional producer, you’ll need to set
enable.idempotence=true- Set retries to a high number (leave default)
retries=2147483647 acks=alltransactional.id- set a transactional ID for this process instance. To configure a transaction aware consumer, you should set -isolation.level=read_committed-enable.auto.commit=false
The transactional producer and consumer should sit in the same process space in order for the transactional producer to be able to send the consumed offsets as part of the transaction
Project Setup
We’ll be using the rdkafka Rust module to implement EOS transactions, however you can use any other Rust Kafka module to do this. Additionally we’ll be working on the Tokio async framework to make use of rdkafka’s FutureProducer and StreamConsumer async functionality.
Transactional Producer API
Modern Kafka libraries will expose the transactional producer API methods through a Producer class. Taking a look into rdkafka’s documentation, we can see that it exposes five methods that help manage transactions to the TXN(Transaction) Coordinator.
fn init_transactions<T: Into<Timeout>>(&self, timeout: T) -> KafkaResult<()>;fn begin_transaction(&self) -> KafkaResult<()>;fn send_offsets_to_transaction<T: Into<Timeout>>( &self, offsets: &TopicPartitionList, cgm: &ConsumerGroupMetadata, timeout: T, ) -> KafkaResult<()>;fn commit_transaction<T: Into<Timeout>>( &self, timeout: T, ) -> KafkaResult<()>;fn abort_transaction<T: Into<Timeout>>(&self, timeout: T) -> KafkaResult<()>;
init_transactions()
When the process is started - it needs to initiate transactions with the transaction coordinator. This method only needs to be called once per start up - and performs some useful operations. First - it checks if transactional.id is set in the producer’s configuration. If it isn’t it will throw an error.
This method will ensure that any transactions initiated by a previous producer with the same transactional.id are completed. Any transactions left open by such previous producer will be aborted - and those stale instances will have their epoch bumped by the newest producer - effectively fencing off those producers. Once these method has been run successfully - messages that are sent by this producer can only be a part of a transaction.
begin_transactions()
This method begins a transaction, which will send a request to the TXN Coordinator to mark the TXN log as begin_transaction. If this method completes successfully - all messages sent will be apart of the transaction.
Additionally at least one transaction operation must be performed before transaction.timeout.ms to avoid timing out the transaction. When a transaction times out - it will be aborted.
send_offsets_to_transactions()
This method is the magic that makes EOS transactions work within Kafka workflows. A successful call means that offset markers sent using this method - are bound to the transaction - and are committed only if the transaction has been committed successfully. Therefore - if there’s an error - or a need to “roll back” sent messages - we can abort the transaction in order for downstream consumers (with isolation.level=read_committed) to skip these aborted messages. Upon producer restart we can process these messages again.
commit_transaction() and abort_transaction()
Mark the transaction as finished or aborted. Committing will let downstream consumers see the messages apart of that transaction, while aborting will hide these messages from those consumers. - committing will flush all outstanding messages (messages sent before this method was called). Messages that end up failing will throw an exception on this method, where the code has to then abort the transaction if the error is abortable. We’ll go more in depth with this in the code. - aborting will purge all outstanding messages After a successful call to either of these methods, the producer may begin another transaction.
Create Consumer
// Define a new type for convenience
type LoggingConsumer = StreamConsumer<LoggingConsumerContext>;
// this consumer is a StreamConsumer which doesn't have to issue .poll() explicitly
fn create_consumer(brokers: &str, group_id: &str, topic: &str) -> LoggingConsumer {
let context = LoggingConsumerContext;
let consumer: LoggingConsumer = ClientConfig::new()
.set("group.id", group_id)
.set("bootstrap.servers", brokers)
.set("enable.partition.eof", "false")
.set("auto.offset.reset", "earliest")
.set("session.timeout.ms", "6000")
// turn off auto commit
.set("enable.auto.commit", "false")
// some API's will expose this key which keeps track of the in-memory offset store
// turn this off too
.set("enable.auto.offset.store", "false")
.set("isolation.level","read_committed")
.set_log_level(RDKafkaLogLevel::Debug)
.create_with_context(context)
.expect("Consumer creation failed");
consumer
.subscribe(&[topic])
.expect("Can't subscribe to specified topic");
consumer
}
- This configuration turns off the auto commit functionality of the consumer - which is important because we don’t want to commit offsets before a transaction completes.
- consumer should read committed messages in order to keep the EOS semantics alive - though it is optional to do. If
read_uncommittedis set - then the consumer will read aborted messages.
Create Producer
fn create_producer(brokers: &str) -> FutureProducer {
ClientConfig::new()
.set("bootstrap.servers", brokers)
.set("queue.buffering.max.ms", "0") // Do not buffer
.set("transactional.id","example-eos-pid")
.set("transaction.timeout.ms","10000")
.create()
.expect("Producer creation failed")
}
Sets the transactional.id and the transaction.timeout.ms. To choose a transactional ID - usually it’s best to choose an ID that maps the process to it’s assigned topic-partition - having an upper bound of the number of topic-partitions the producer is mapped to. Reason being - if a transaction ID is created from a producer that died - that created a new transactional ID - it doesn’t reap the benefits of fencing.
A list of all configurations can be seen here
Main Loop
let consumer = create_consumer(brokers, group_id, input_topic);
let producer = create_producer(brokers);
// create this producer to setup for transactions
let init_trans_res = producer.init_transactions(Duration::from_secs(5));
if init_trans_res.is_err(){
init_trans_res.inspect_err(|e| eprintln!("Unable to initialize transaction {e}")).expect("Exiting out of program");
}
println!("Starting loop");
loop {
match consumer.recv().await {
Err(e) => {
warn!("Kafka error: {}", e);
}
Ok(m) => {
// Send a copy to the message to every output topic in parallel, and wait for the
// delivery report to be received.
println!("{:?}",m.payload_view::<str>().expect("Couldn't parse message into string"));
// we want to begin a transaction now
producer.begin_transaction().expect("Failed to begin transaciton");
let send_futs:Result<Vec<(i32, i64)>, (rdkafka::error::KafkaError, rdkafka::message::OwnedMessage)>
= future::try_join_all(output_topics.iter().map(|output_topic| {
/*
Perform some non blocking quick CPU action or an IO async operation
Usually parsing transforms, validation, etc can be performed here
*/
let mut record = FutureRecord::to(output_topic);
if let Some(p) = m.payload() {
record = record.payload(p);
}
if let Some(k) = m.key() {
record = record.key(k);
}
producer.send(record, Duration::from_secs(1))
}))
.await;
match send_futs {
Ok(_) => {
// this essentially will commit the offsets every message received
// mark the consumer's position with the current transaction
producer.send_offsets_to_transaction(
&consumer.position().expect("Couldn't parse consumer position"),
&consumer.group_metadata().expect("Couldn't parse consumer group metadata"),
Duration::from_secs(10)
).expect("Failed to send offsets to transaction");
// Commits the transaction - effectively committing the consumer's offsets
// and letting downstream consumers read the messages
let commit_res = producer.commit_transaction(Duration::from_secs(2));
match commit_res {
Err(KafkaError::Transaction(rde)) => {
if rde.txn_requires_abort() {
println!("Transaction requires an abort!");
producer
.abort_transaction(Duration::from_secs(2))
.expect("Failed to abort transaction");
}
}
Err(err) => {
panic!("Fatal error: {:?}", err);
}
Ok(_) => {}
}
},
Err((e,_m)) => {
println!("{:?}",e);
match e{
KafkaError::Transaction(rde) =>{
if rde.txn_requires_abort(){
println!("Transaction requires an abort!");
producer.abort_transaction(Duration::from_secs(2)).expect("Failed to abort transaction");
}
},
// panic for all other errors
_ => {
panic!("Fatal error");
}
}
}
}
}
}
}
Let’s break down this code.
Upon startup, the application will create the transactional producer and consumer. The consumer will subscribe to a list of topics - and get assigned a various number of topic-partitions.
The application - before it performs any message consumption - will call init_transactions.
Once that completes - the application can now start processing messages. Within the loop block, the application will receive a message from the consumer, and then begin_transaction. The application will then perform some type of processing on the consumed message - either in parallel or concurrently (if processing IO). Once the task has finished, the transactional producer will send that message off to the output topic.
This example is not suitable for long running CPU bound tasks.
Once the message has been sent, the producer can send the consumer’s consumed offsets along with the transaction, and then commit the transaction.
This is the happy path - no errors, no brokers failing, no DNS errors, no socket timeouts, no parsing failures - no failures.
Example
Here we’ve set up a kafka-console-producer.sh and a kafka-console-consumer.sh which are scripts that kafka provides in it’s bin/ directory. These essentially produce/consumer messages off the specified topics. We’ve set up a local cluster and created two topics, input-topic-0 and output-topic-0.

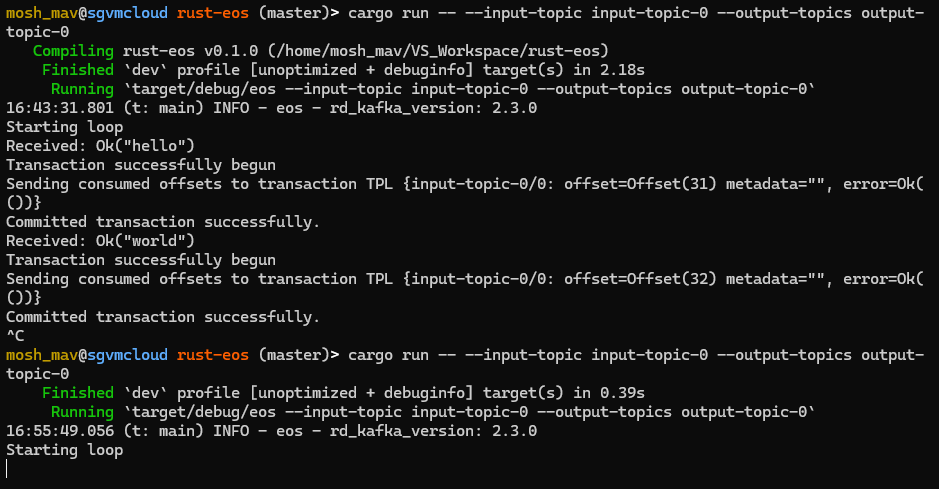
We can now run our process specifying the input and output topics to consume and produce from. Below on the left screen, we’ve compiled and ran the example to ingest messages from input-topic-0 and produce messages to output-topic-0. On the right screen we have the producer and consumer, which will receive messages from the example and produce messages from the example.
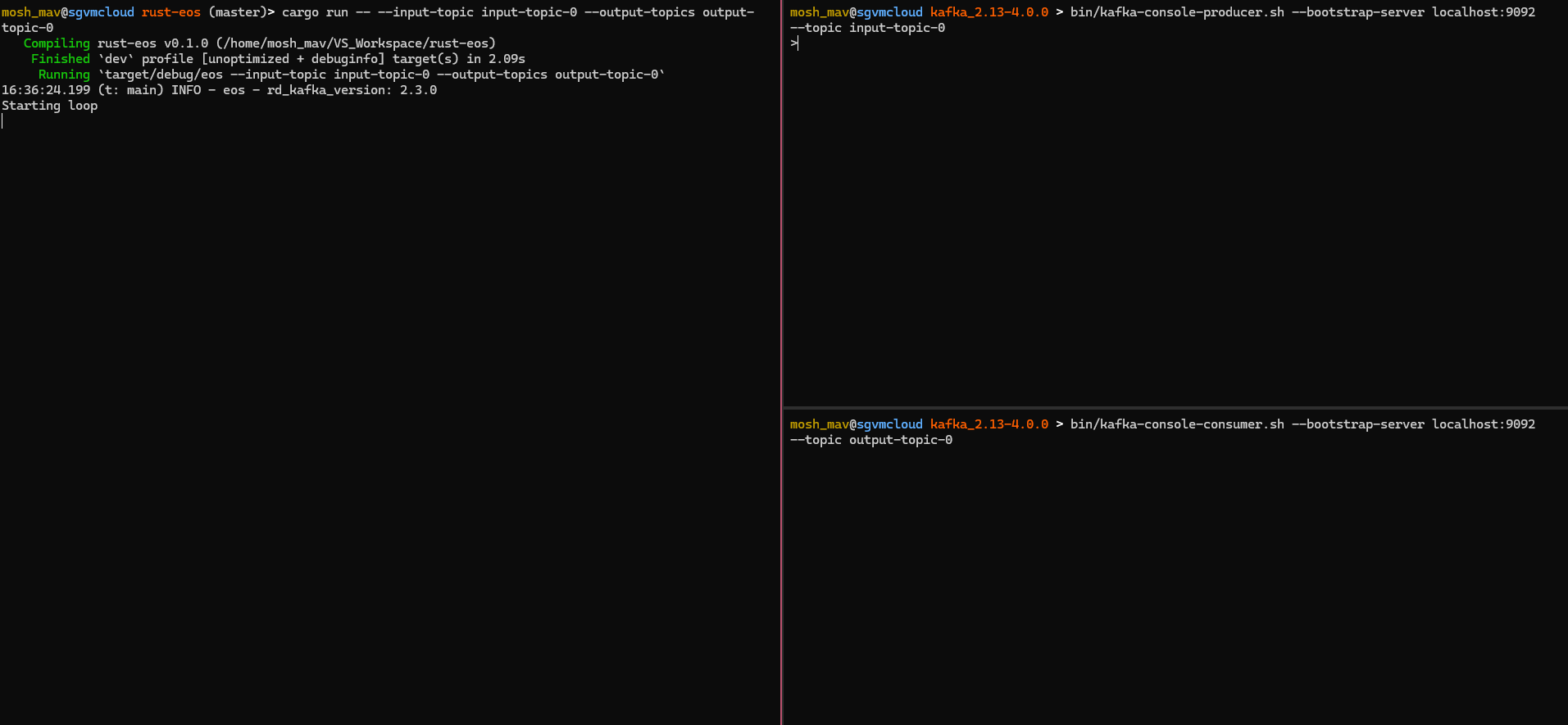
In our console producer, let’s send “hello” and “world” to input-topic-0, which is received by our program.
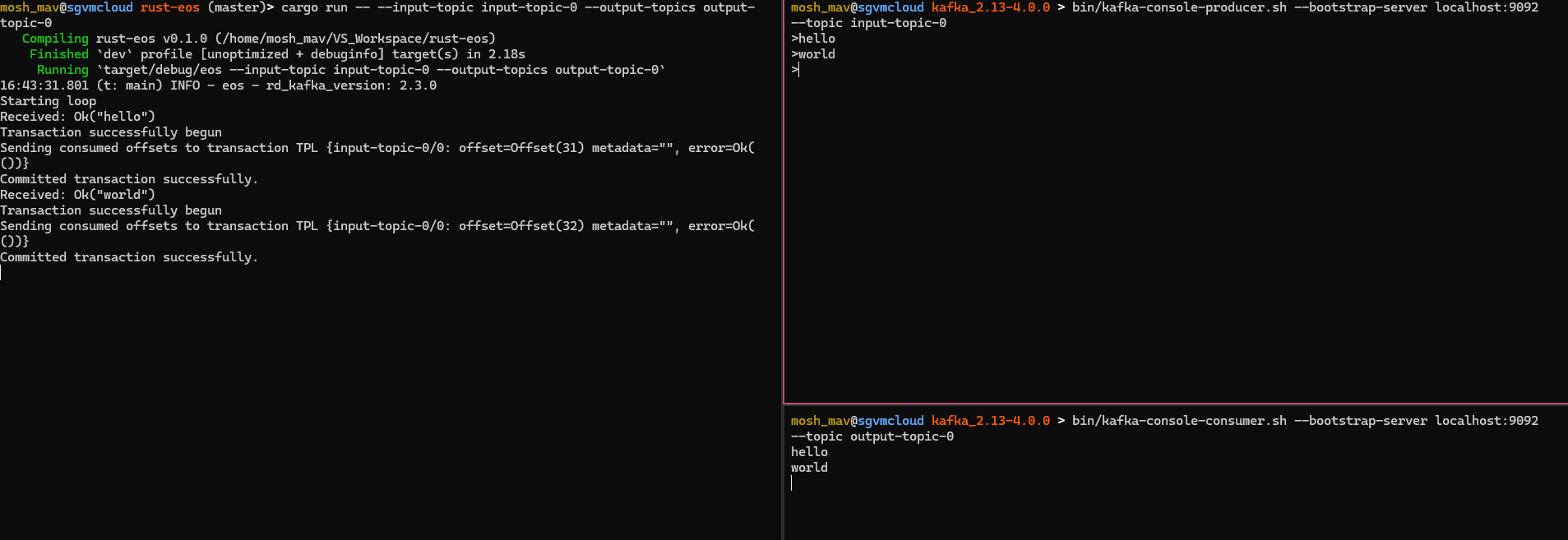
The output clearly outlines our main loop. The rust-eos example waits until it receives a message from our console-producer. Once it receives the message - it will begin the transaction - and once that successfully returns we can now process the task safely. In this case it’s producing it out to output-topic-0. If no errors occurred in the send_futs then we know that all messages were sent and acked by the broker, thus in the Ok(_) block we could move on. The producer needs to associate the consumed offsets of the consumer with the transaction - which we can get from consumer.position(). If that message succeeds - we can successfully commit the transaction. After committing the transaction we can now continue to receive messages.
kafka-transactions.sh
Kafka provides a nifty script called kafka-transactions.sh in where you could see ongoing transactions within the cluster.

Here we can see the CoordinatorId - which is the transaction leader(broker) that is responsible for the transaction. Additionally we can see our transactional.id and producer’s epoch. If we restart our example eos binary we’ll see that the epoch will get bumped to 10.
Restarting the binary.

we can can also see that it’s transaction state is
Empty. This means that the transaction has been registered with the coordinator - however no transaction has begun - therefore any produces without beginning will run into an erroneous state error.
Unhappy Path
Now that we’re familiar with the happy path - we need to go through the examples of the unhappy path - which development and production clusters are rife with. In this article we’ll go over how our simple rust-eos example that we’ve created behaves in the face of failure at different parts of the loop. However we won’t go over ways to handle errors when they appear. That’s another article entirely.
these next examples will have the same loop as specified above, I’ll just be adding in prints and panics in various places to show case different types of errors.
Duplicate Transactional ID
Let’s say that we have two instances of the rust-eos binary - that both share the same transactional id. Let’s also assume they are exact copies of each other - and ingest from the same input and output topics - in our example input-topic-0. For the sake of simplicity - we’ll also assume that these binaries don’t share the same consumer group - therefore both can ingest from input-topic-0 at the same time. Ok what does this mean? If both of these processes share the same transactional.id - you’re enabling EOS across both processes - however if the consumer groups are different you’re essentially processing messages fromm input-topic-0 twice. In this case - the rust-eos process that has the latest epoch will fence out the older rust-eos process. Only one of these processes will process the messages.
Let’s see it in this example. We have two eos-rust processes, which share the same transactional id, but different group id’s.
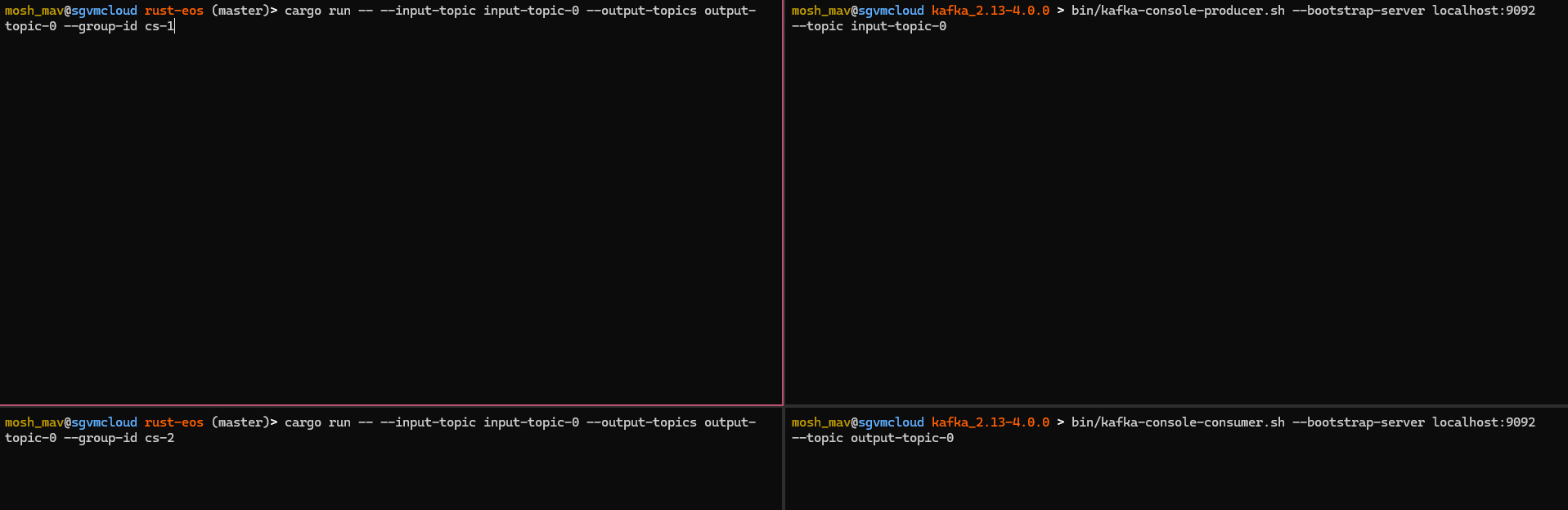
Sending “hello” to input-topic-0 will result in one of these processes being FENCED.
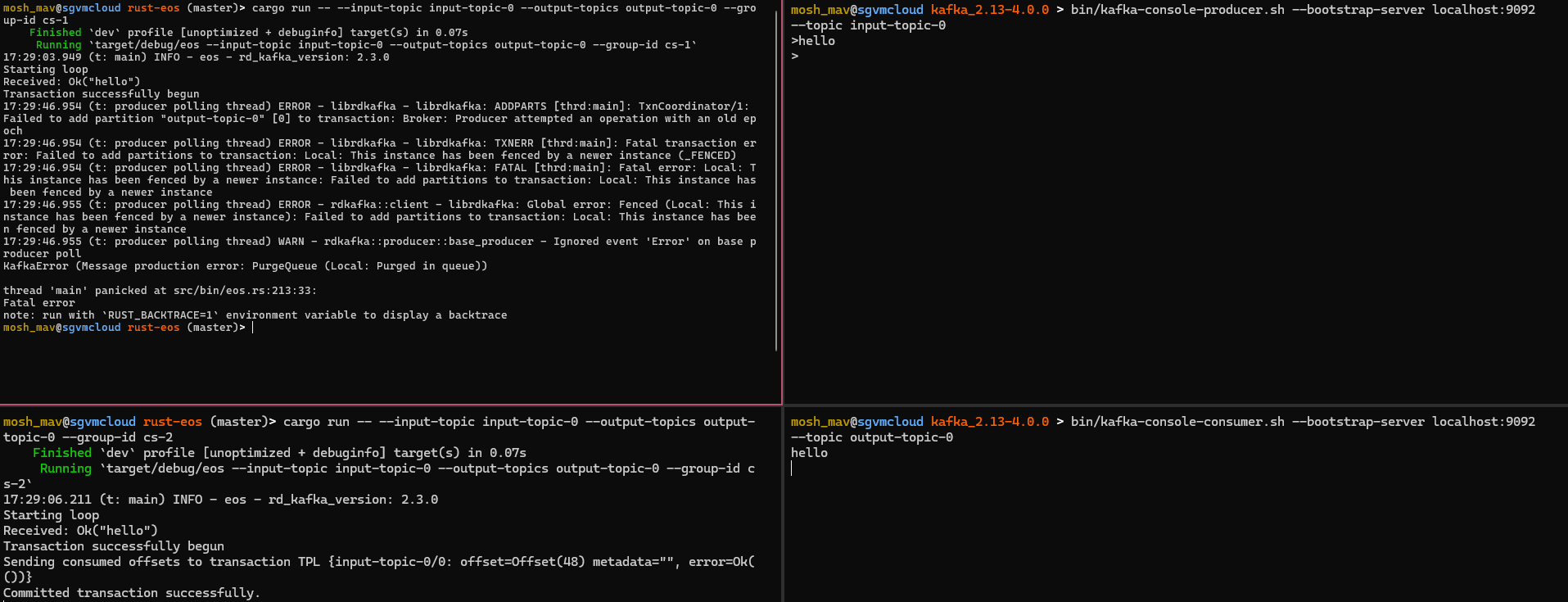
We can see that both of the processes consumed from the input topic, however the one with the oldest epoch is the only one that processed the message. The other process that was FENCED just closes out.
Ok that’s cool - what if the processes are within the same consumer group?
Well that’s pretty similar - remember only one producer with a mapped transactional id can produce to the transaction - even if it’s mapped to consume from different/same topic-partitions. When two processes are consuming the same topic-partition - only the one with the newest epoch will be able to process the messages. Even if the process with the newest epoch doesn’t receive the messages initially (due to consumer group rebalancing) - it will be able to process the messages once it’s able to be assigned.
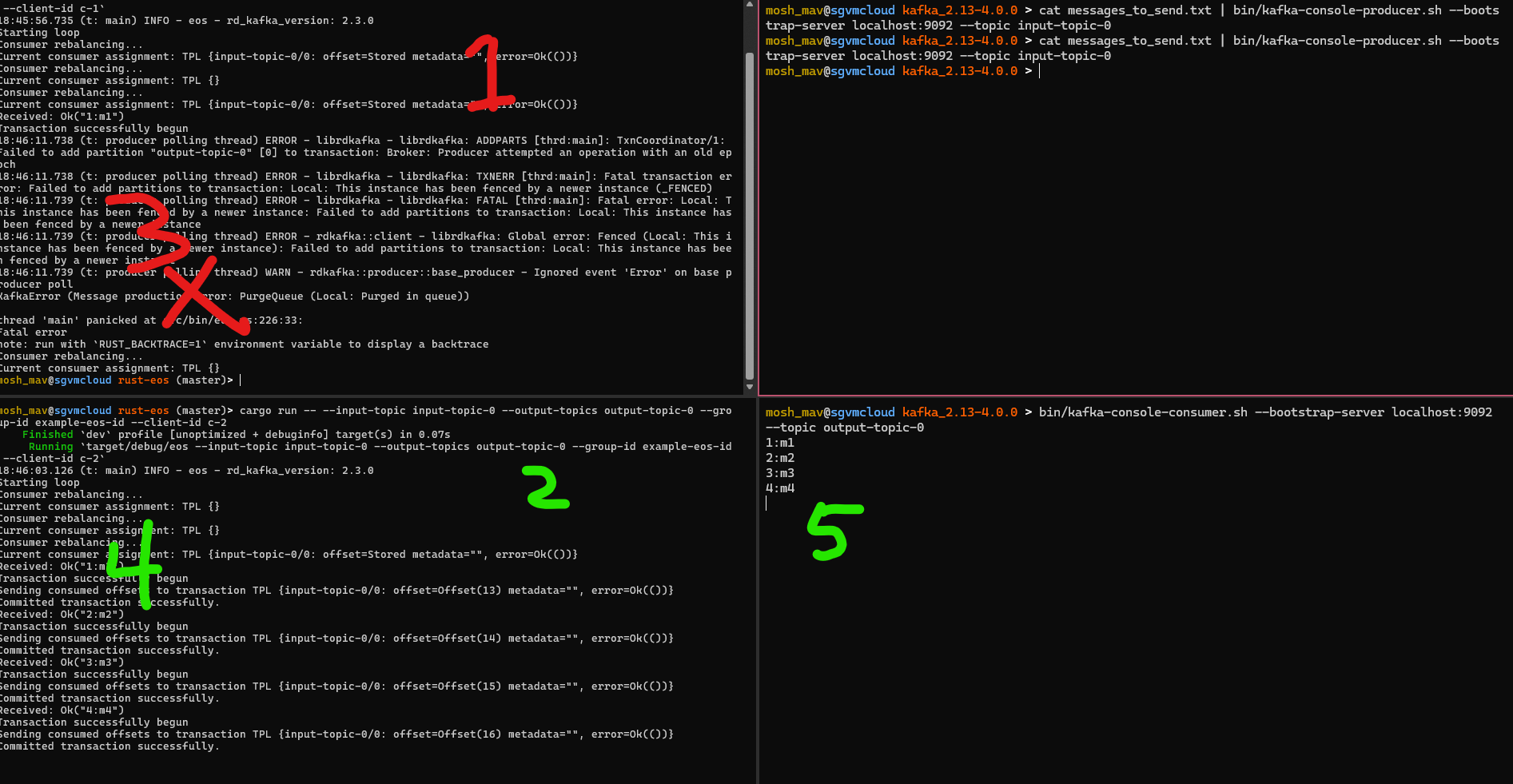
Let’s look at this above screen shot that shows how a zombie process works
- We’ve launched the rust-eos process here. We can see that it’s assigned to
input-topic-0at partition 0. When 2. joined - it briefly rebalanced the consumers - but then was able to still keep the same partition. - is created at a later point in time - thus has a higher epoch
- we then sent messages to the input topic.
- We see that 1. receives the message and tries to perform the transactional loop - however it gets fenced, and exits.
- Now the fresher instance 2. is assigned to partition 0 and is able to process those messages.
We can clearly see that only the newest instance with the same transactional.id is able to perform transactional operations within kafka.
Task workload failures
If the rust-eos process crashes during message processing, regardless if it happened before or after the producer send, the restarted instance will pick off where the consumer left off.
if let Some(k) = m.key() {
record = record.key(k);
}
panic!("Fatal error seen while processing message");
producer.send(record, Duration::from_secs(1))
adding a simulated panic before the producer send. This can easily just be a KafkaError returned from
producer.send.
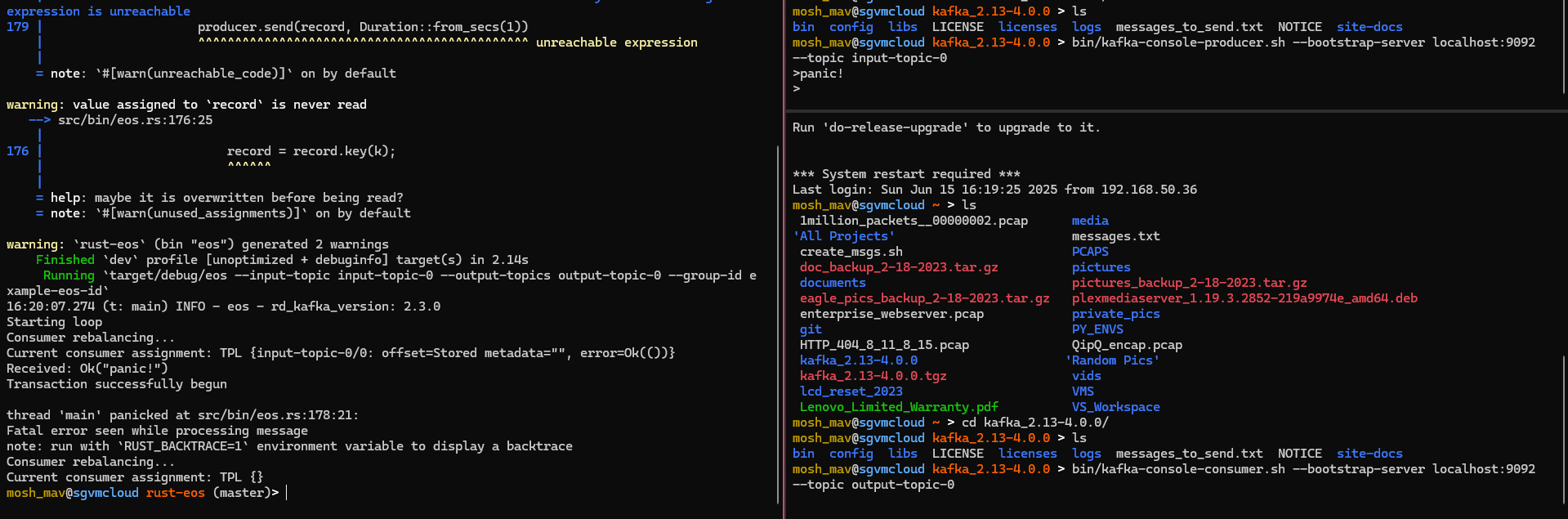
the rust-eos process failed, and did not send out a produce to the output topic.
When the process restarts, it re-consumes the message and will try again. Even though it tries again - due to our EOS semantics it will only be successfully processed once.
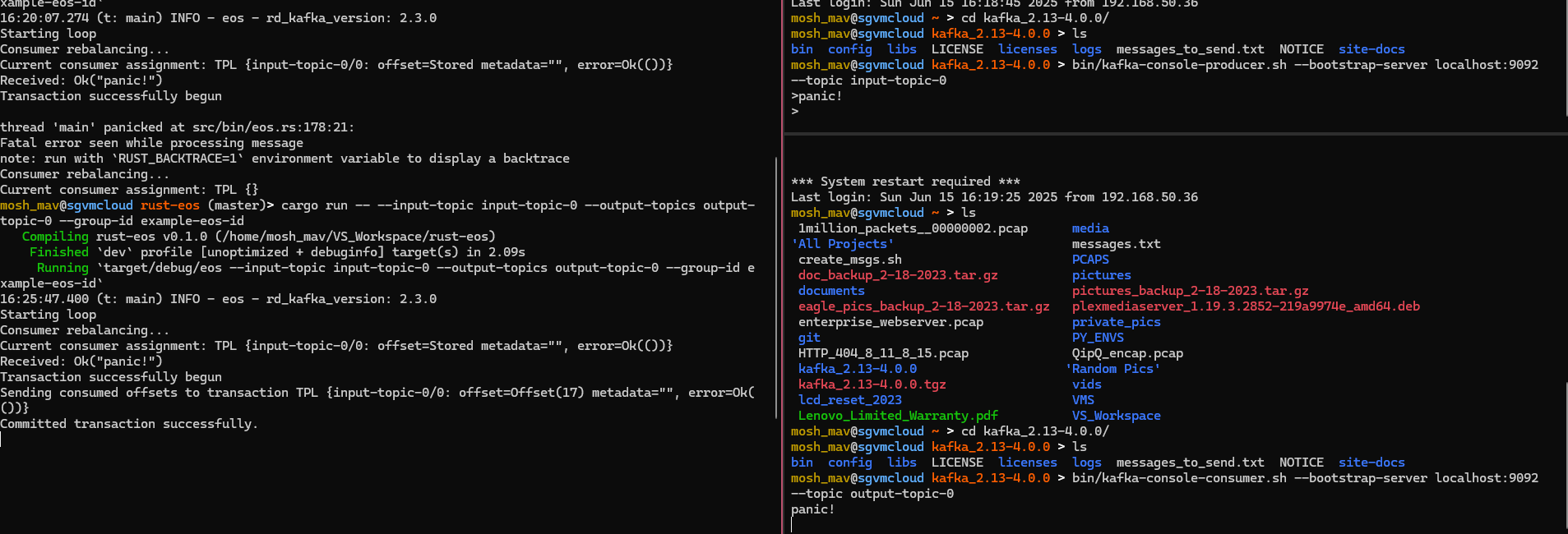
It’s important to remember that transactions are completed if the commit or abort methods go through.
Commit or abort fails
During a commit or abort failure, the transaction is put into an invalid state. However this could happen due to the process crashing before the transaction could be completed, or errors in application code causes an invalid state. So what happens when the commit or abort fails?
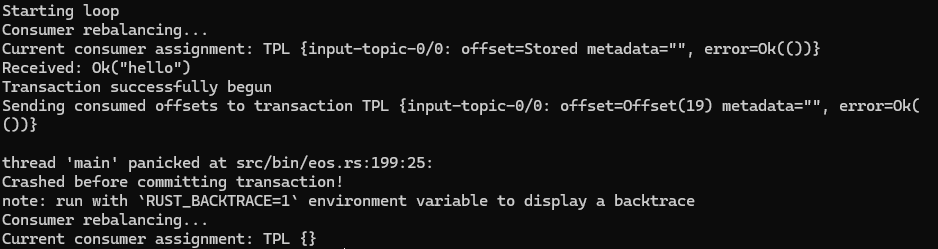
We can see that the consumer was able to receive the message and begin the transaction - even sending the consumed offsets to the transaction coordinator. However it panicked before committing the transaction.
Using kafka-transactions.sh, we can check that state it was left in the transaction log.

The process left the transaction state in Ongoing, and we can also see that it sent the message out to two topic partitions, __consumer_offsets-38 and output-topic-0-0. Downstream consumers still do not see the message because the transaction has not completed (and in read_committed mode). The transaction will be left open until our configured transaction.timeout.ms time has expired - where the transaction coordinator will then preemptively abort the transaction.
note when aborting the transaction the broker is configured to check every
transaction.abort.timed.out.transaction.cleanup.interval.ms, which is why it seems to exceedtransaction.timeout.ms.
If we start up the process again within that window - we’ll actually get a warning when init_transactions. This will fence out any previous transaction operations, and then continue to acquire the internal producer ID and update it’s epoch.
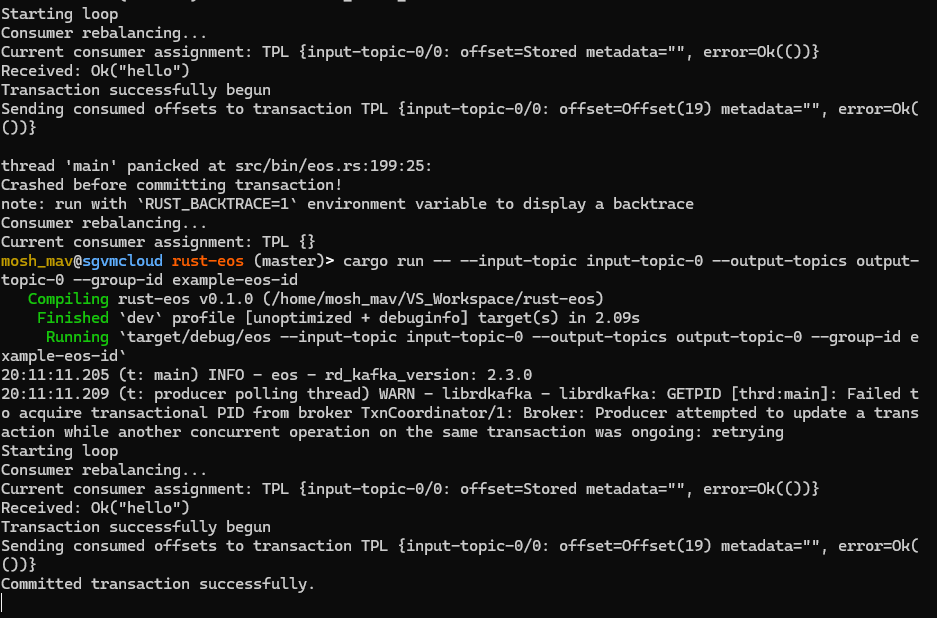
If we look carefully, we can also see that the CurrentTransactionStartTimeMS is the same across epochs, because the restarted instance is technically carrying over the same transaction from the previous instance. However - we get that warning because the epoch has been bumped.

Improvements and Next Steps
Our implementation of EOS transactions in Rust can be greatly improved. You might have noticed that the workflow is essentially a two phase commit process, and that our main loop commits every single time a message is received by the consumer. We can greatly improve the processing time by implementing batching - to commit after X messages are consumed.
In our example - we mainly panic in the face of errors, and issue a restart pattern. That could be fine, but we can also implement different techniques to retry failed messages without restarting the process.
Additionally, it’s important to note that EOS that we’ve covered today is only applicable within the Kafka ecosystem. Operations on messages that touch external databases, API’s, etc aren’t guaranteed to be exactly once. I hope to cover how to employ EOS for external processes in Kafka in a future article.